Il Natural Language Processing (NLP) è un ramo dell'intelligenza artificiale che permette ai computer di comprendere, interpretare e generare il linguaggio umano. Questa tecnologia combina linguistica computazionale e machine learning per analizzare testi, estrarre informazioni e individuare pattern. Applicazioni come chatbot, motori di ricerca e analisi dei social media si basano ampiamente sul NLP per gestire enormi quantità di dati testuali.
Tra le librerie più potenti per il NLP in Python, spaCy si distingue per le sue elevate prestazioni, il supporto a modelli pre-addestrati e la capacità di gestire grandi volumi di testo in modo rapido ed efficiente. Sviluppata per applicazioni a livello industriale, spaCy fornisce un'architettura ottimizzata per attività complesse come l'analisi del sentiment, il riconoscimento di entità e il parsing sintattico.
Negli ultimi anni, il campo del NLP ha visto progressi rivoluzionari grazie all'avvento dei modelli di linguaggio transformer come BERT, GPT e T5. Questi modelli hanno trasformato radicalmente le capacità dei sistemi NLP, permettendo una comprensione più profonda del contesto e delle sfumature linguistiche. SpaCy ha integrato queste innovazioni mantenendo la sua filosofia di design incentrata sulla velocità e l'usabilità.
La forza di spaCy risiede nella sua pipeline di elaborazione modulare che permette di personalizzare facilmente i flussi di lavoro in base alle esigenze specifiche. Dal tokenizing alla lemmatizzazione, dal part-of-speech tagging al dependency parsing, ogni componente è progettato per lavorare in sinergia con gli altri, offrendo risultati accurati con il minimo sforzo di configurazione.
Per chi si avvicina al mondo del NLP, spaCy rappresenta un punto d'ingresso ideale, combinando una sintassi intuitiva con funzionalità avanzate, documentazione esaustiva e una comunità attiva di sviluppatori. Sia che si tratti di analizzare documenti legali, estrarre informazioni da articoli medici o costruire assistenti virtuali intelligenti, spaCy fornisce gli strumenti necessari per trasformare il testo grezzo in conoscenza strutturata e actionable.
SpaCy è una libreria open source per il NLP progettata per l'uso in produzione. A differenza di altre librerie, spaCy non è pensata per la ricerca accademica, ma per l'implementazione di applicazioni robuste e performanti. La sua architettura è costruita per sfruttare modelli di deep learning ottimizzati e per gestire flussi di dati di grandi dimensioni senza sacrificare la velocità.
Le funzionalità di spaCy includono la tokenizzazione del testo, l'assegnazione delle parti del discorso (POS tagging), il riconoscimento delle entità nominate (NER), il parsing delle dipendenze grammaticali e la lemmatizzazione. Grazie al supporto multilingue, spaCy può analizzare testi in inglese, italiano, francese e altre lingue, consentendo l'implementazione di soluzioni NLP internazionali.
SpaCy viene impiegato in vari contesti, come l'estrazione di informazioni da grandi dataset testuali, l'analisi del sentiment per comprendere le opinioni degli utenti e la costruzione di chatbot capaci di identificare intenti e contesti. Nelle applicazioni di content analysis, spaCy è utilizzato per individuare parole chiave, riconoscere entità come nomi di persone, luoghi, date e importi monetari, e per analizzare la struttura sintattica delle frasi, rendendo il testo strutturato e interpretabile per ulteriori elaborazioni.
L'analisi grammaticale e la lemmatizzazione sono particolarmente utili per normalizzare i testi, rendendo il contenuto uniforme e facilitando l'analisi semantica. Inoltre, spaCy può essere integrato in pipeline di machine learning per il training di modelli personalizzati, rendendolo un componente essenziale per progetti avanzati di intelligenza artificiale.
Utilizzo pratico di spaCy per i tasks NLP più comuni
Per utilizzare spaCy, è necessario installarlo e scaricare un modello linguistico. L'installazione avviene tramite il comando pip install -U spacy. Una volta installata la libreria, è possibile scaricare un modello pre-addestrato per l'analisi linguistica, come en_core_web_sm per l'inglese.
Dopo aver caricato il modello, si può iniziare ad analizzare il testo. La libreria suddivide il testo in token, identifica le parti del discorso e rileva le entità nominate.
Esempio di utilizzo:
import spacy
nlp = spacy.load("it_core_news_sm")
text = "Elon Musk ha fondato SpaceX nel 2002 e Tesla nel 2003."
doc = nlp(text)
for token in doc:
print(f"Token: {token.text}, Lemma: {token.lemma_}, POS: {token.pos_}, Stopword: {token.is_stop}")
for ent in doc.ents:
print(f"Entità: {ent.text}, Tipo: {ent.label_}")
print("Frasi nel testo:")
for sent in doc.sents:
print(sent)
print("Dipendenze:")
for token in doc:
print(f"{token.text} - {token.dep_} - {token.head.text}")
print("Chunking:")
for chunk in doc.noun_chunks:
print(chunk)Il codice presentato è un esempio pratico che mostra le capacità di spaCy nella lingua italiana, sfruttando il modello it_core_news_sm. Questo modello, appositamente addestrato per l'italiano, consente di eseguire una serie di operazioni NLP fondamentali, tra cui tokenizzazione, lemmatizzazione, rilevamento delle stop words, analisi sintattica, riconoscimento di entità nominate e individuazione dei chunk nominali.
Il testo di esempio scelto — "Elon Musk ha fondato SpaceX nel 2002 e Tesla nel 2003." — viene analizzato passo dopo passo per dimostrare le funzionalità di spaCy. Dopo il caricamento del modello italiano, il testo viene convertito in un oggetto doc, che rappresenta l'analisi strutturata del testo da parte di spaCy. A partire da questo oggetto doc, vengono estratti i singoli token del testo, ovvero le parole o i segni di punteggiatura, insieme alle loro caratteristiche linguistiche.
In particolare, per ogni token vengono stampate quattro informazioni chiave:
-
Token: il testo originale del token.
-
Lemma: la forma base o radice del token, utile per normalizzare il contenuto testuale.
-
POS (Part-Of-Speech): la categoria grammaticale assegnata al token, come verbo, nome, aggettivo, ecc.
-
Stopword: un valore booleano che indica se il token è una stop word, ovvero una parola comune e poco significativa come "e", "nel", "ha".
Successivamente, il codice estrae le entità nominate presenti nel testo. Le entità sono elementi semantici rilevanti come nomi di persone, organizzazioni, date e quantità numeriche. In questo esempio, spaCy identifica "Elon Musk", "SpaceX" e "Tesla" come nomi propri e "2002" e "2003" come date.
Il codice prosegue quindi con l'estrazione delle frasi presenti nel testo, suddividendole in base alla struttura sintattica. Questa fase consente di gestire testi più lunghi o complessi in modo più granulare.
La sezione dedicata alle dipendenze sintattiche mostra le relazioni grammaticali tra i token. Ogni token viene analizzato in relazione al suo head, ovvero il termine principale della frase a cui è legato, e al tipo di dipendenza (dep_), come soggetto, oggetto o complemento.
Infine, il codice evidenzia i chunk nominali, ovvero i gruppi di parole centrati intorno a un nome, che rappresentano le unità semantiche più rilevanti per una successiva analisi semantica o sintattica.
Questo esempio, oltre a dimostrare le capacità di spaCy nel gestire il testo in italiano, evidenzia la modularità della libreria, che consente di aggiungere ulteriori componenti o pipeline per analisi personalizzate e più avanzate.
Addestrare un modello spaCy
Il più delle volte, i modelli pre-addestrati offerti da spaCy sono sufficienti per compiti generici come l'estrazione di entità comuni, la lemmatizzazione o il part-of-speech tagging. Tuttavia, quando si lavora su contesti specifici, come il linguaggio legale, medico o finanziario, diventa essenziale addestrare modelli su misura per migliorare l'accuratezza e la rilevanza dei risultati.
SpaCy permette di addestrare le proprie pipeline NLP, consentendo di personalizzare ogni componente, come il tokenizer, il POS tagger, il parser sintattico e il riconoscitore di entità nominate (NER). Il processo di training in spaCy si basa su un file di configurazione che specifica i dettagli del modello, i dati di addestramento, gli hyperparameter e le pipeline da includere.
Per creare un file di configurazione personalizzato, spaCy fornisce un generatore interattivo disponibile qui: https://spacy.io/usage/training. Questo strumento permette di selezionare la lingua, il tipo di modello (da zero o basato su un modello pre-addestrato) e le pipeline da includere. Il configuratore genera un file .cfg che può essere utilizzato per avviare il training.
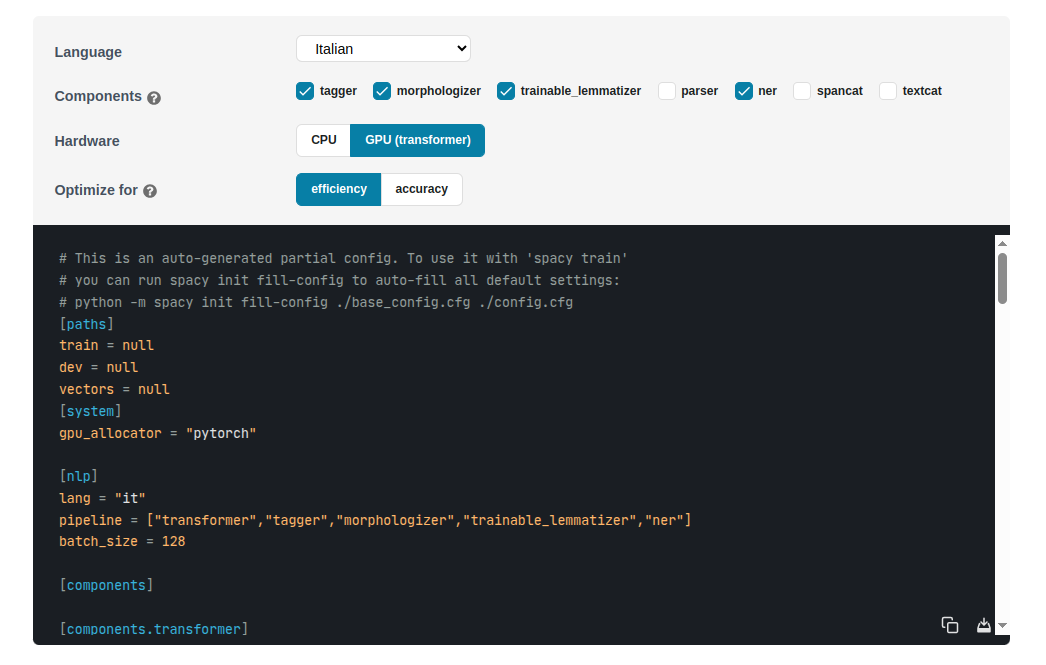
Il file di configurazione consente di definire in modo dettagliato quali componenti addestrare, quali esclusioni applicare e come gestire i pesi dei modelli. Ad esempio, si può scegliere di addestrare solo il componente NER, lasciando invariati gli altri componenti, o viceversa.
Il training di spaCy supporta anche l'uso di vettori word embeddings specifici per il dominio, migliorando ulteriormente la capacità del modello di comprendere terminologia settoriale. Inoltre, spaCy offre strumenti per valutare le prestazioni del modello addestrato, come metriche di precisione, recall e F1-score, essenziali per ottimizzare i parametri del modello e ottenere i migliori risultati possibili nel contesto applicativo di riferimento.
Esempio di training
Vediamo come preparare un dataset per addestrare tre pipeline di spaCy : senter, lemmatizer e ner.
[{"text": "Federico ha compiuto 56 anni a Saratov ieri.", "tokens": [{"text": "Federico", "is_sent_start": true, "lemma": "Federico"}, {"text": "ha", "is_sent_start": false, "lemma": "avere"}, {"text": "compiuto", "is_sent_start": false, "lemma": "compiere"}, {"text": "56", "is_sent_start": false, "lemma": "56"}, {"text": "anni", "is_sent_start": false, "lemma": "anno"}, {"text": "a", "is_sent_start": false, "lemma": "a"}, {"text": "Saratov", "is_sent_start": false, "lemma": "Saratov"}, {"text": "ieri", "is_sent_start": false, "lemma": "ieri"}, {"text": ".", "is_sent_start": false, "lemma": "."}], "entities": ["Federico", "56", "Saratov"], "labels": ["PERSON", "NUMBER", "CITY"]}]Il dataset di esempio è strutturato come una lista di oggetti JSON, ciascuno dei quali rappresenta una frase annotata con informazioni dettagliate per il training di vari componenti di spaCy. Vediamo in dettaglio la struttura di un singolo oggetto:
-
Campo "text": Contiene la frase originale che verrà utilizzata per il training. Esempio: "Federico ha compiuto 56 anni a Saratov ieri."
-
Campo "tokens": È una lista di oggetti che rappresenta i singoli token del testo. Ogni token è descritto da tre proprietà essenziali:
-
text: il testo del token. -
is_sent_start: un booleano che indica se il token è l'inizio di una nuova frase. Questo campo è fondamentale per addestrare il componentesenterdi spaCy, che individua i confini delle frasi. -
lemma: la forma base o radice del token, utilizzata per addestrare il componentelemmatizer.
-
-
Campo "entities": Una lista che elenca le entità presenti nel testo. Le entità sono termini specifici che verranno etichettati con le categorie definite nel campo
labels. -
Campo "labels": Una lista di etichette che specificano il tipo di ciascuna entità elencata in
entities. Le etichette seguono lo stesso ordine degli elementi inentities.
Questa struttura non solo consente di addestrare il componente ner per il riconoscimento di entità, ma fornisce anche i dati necessari per addestrare senter (identificazione dei confini di frase) e lemmatizer (normalizzazione dei token). In questo modo, un singolo dataset permette di ottimizzare più componenti di spaCy contemporaneamente, rendendo il modello più versatile e accurato per il dominio di riferimento.
Di seguito il notebook per addestrare il modello con il nostro dataset
!pip install spacy-lookups-data
!python -m spacy download it_core_news_md
import json
import os
import random
import spacy
from spacy.tokens import DocBin
import spacy_lookups_data
from spacy.pipeline import Lemmatizer
from spacy.lookups import Lookups
def prepare_spacy_data(entry):
"""
Prepares SpaCy-compatible data for a single entry, ensuring no overlapping entities.
Args:
entry (dict): A dictionary with keys 'text', 'entities', and 'labels'.
Returns:
tuple: (text, {"entities": [(start, end, label), ...]})
"""
text = entry["text"]
entities = entry.get("entities", [])
labels = entry.get("labels", [])
# Combine entities and labels into a list of tuples and sort by entity length (descending)
sorted_entities = sorted(zip(entities, labels), key=lambda x: len(x[0]), reverse=True)
entity_annotations = []
marked_positions = set() # Per tenere traccia delle posizioni già utilizzate
for entity, label in sorted_entities:
# Trova tutte le occorrenze dell'entità nel testo originale
start_position = 0
while True:
start_idx = text.find(entity, start_position)
if start_idx == -1:
break
end_idx = start_idx + len(entity)
# Controlla se questa posizione si sovrappone a entità già trovate
overlap = False
for pos in range(start_idx, end_idx):
if pos in marked_positions:
overlap = True
break
if not overlap:
# Aggiungi questa entità alle annotazioni
entity_annotations.append((start_idx, end_idx, label))
# Marca queste posizioni come utilizzate
for pos in range(start_idx, end_idx):
marked_positions.add(pos)
break # Prendi solo la prima occorrenza non sovrapposta
# Continua la ricerca dopo questa occorrenza
start_position = start_idx + 1
# Se dopo aver controllato tutto il testo, l'entità non è stata trovata
if not any(annotation[0] <= text.find(entity) < annotation[1] for annotation in entity_annotations if text.find(entity) != -1):
if text.find(entity) == -1:
print(f"Entity '{entity}' not found in text: '{text}'")
print(entity_annotations)
return text, {"entities": sorted(entity_annotations, key=lambda x: x[0])} # Ordina per posizione iniziale
source_files = '/content/drive/MyDrive/dataset/spacy'
output_dir = '/content/drive/MyDrive/models/spacy'
os.makedirs(output_dir, exist_ok=True)
nlp = spacy.load("it_core_news_md")
doc_bin_train = DocBin(store_user_data=True)
doc_bin_valid = DocBin(store_user_data=True)
# List to store all processed documents
all_docs = []
for filename in os.listdir(source_files):
if filename.endswith(".json"):
file_path = os.path.join(source_files, filename)
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
for entry in data:
if "text" not in entry or "tokens" not in entry:
continue
text = entry["text"]
tokens = entry["tokens"]
doc = nlp.make_doc(text)
try:
for i, token in enumerate(doc):
token.is_sent_start = tokens[i].get('is_sent_start')
token.lemma_ = tokens[i].get('lemma')
except Exception as e:
print(f'Errore nella frase: {text}')
exit()
# Prepare doc and add to list
all_docs.append((doc, entry))
if "entities" in entry and "labels" in entry:
ner_text, ner_annotations = prepare_spacy_data(entry)
ner_doc = nlp.make_doc(ner_text)
ents = []
for start, end, label in ner_annotations["entities"]:
span = ner_doc.char_span(start, end, label=label)
if span:
ents.append(span)
else:
print(f"Skipping entity '{ner_text[start:end]}' due to tokenization mismatch.")
ner_doc.ents = ents
all_docs.append((ner_doc, entry))
# Shuffle all docs and split 85% for training, 15% for validation
random.shuffle(all_docs)
split_index = int(0.85 * len(all_docs))
train_docs = all_docs[:split_index]
valid_docs = all_docs[split_index:]
# Add docs to respective DocBin
for doc, entry in train_docs:
doc_bin_train.add(doc)
for doc, entry in valid_docs:
doc_bin_valid.add(doc)
# Save training and validation files
train_path = os.path.join(output_dir, "train.spacy")
valid_path = os.path.join(output_dir, "valid.spacy")
doc_bin_train.to_disk(train_path)
doc_bin_valid.to_disk(valid_path)
print(f"Training data saved to {train_path}")
print(f"Validation data saved to {valid_path}")
!python -m spacy train '/content/drive/MyDrive/models/spacy/config.cfg' \
--paths.train '/content/drive/MyDrive/models/spacy/train.spacy' \
--paths.dev '/content/drive/MyDrive/models/spacy/valid.spacy' \
--output '/content/drive/MyDrive/models/spacy' \
--gpu-id 0Conclusioni
SpaCy è una libreria indispensabile per chi sviluppa applicazioni NLP avanzate in Python. La sua architettura ottimizzata e il supporto a modelli pre-addestrati permettono di implementare rapidamente soluzioni di analisi del linguaggio naturale. Dalla tokenizzazione alla lemmatizzazione, passando per il riconoscimento di entità e il parsing sintattico, spaCy offre una gamma completa di strumenti per trasformare testo non strutturato in dati utilizzabili. Inoltre, la possibilità di addestrare modelli custom lo rende estremamente flessibile per applicazioni specifiche, garantendo prestazioni elevate anche su dataset di grandi dimensioni.
